在我们使用第三方平台服务的时候,经常需要输入应用的包名和keystore对应的SHA1、SHA-256信息,正常情况下都是使用java的keytool来获取这些信息,其他在Android Studio中使用gradle任务同样可以获取这些信息。
在Android Studio中打开Gradle选项卡,选择选项卡左上角的”Exec Gradle Task”按钮,在弹出的窗口中输入gradle signingReport命令,执行,就可以在输出结果窗口中看到keystore路径、SHA1、SHA-256等信息了。操作过程如下图:
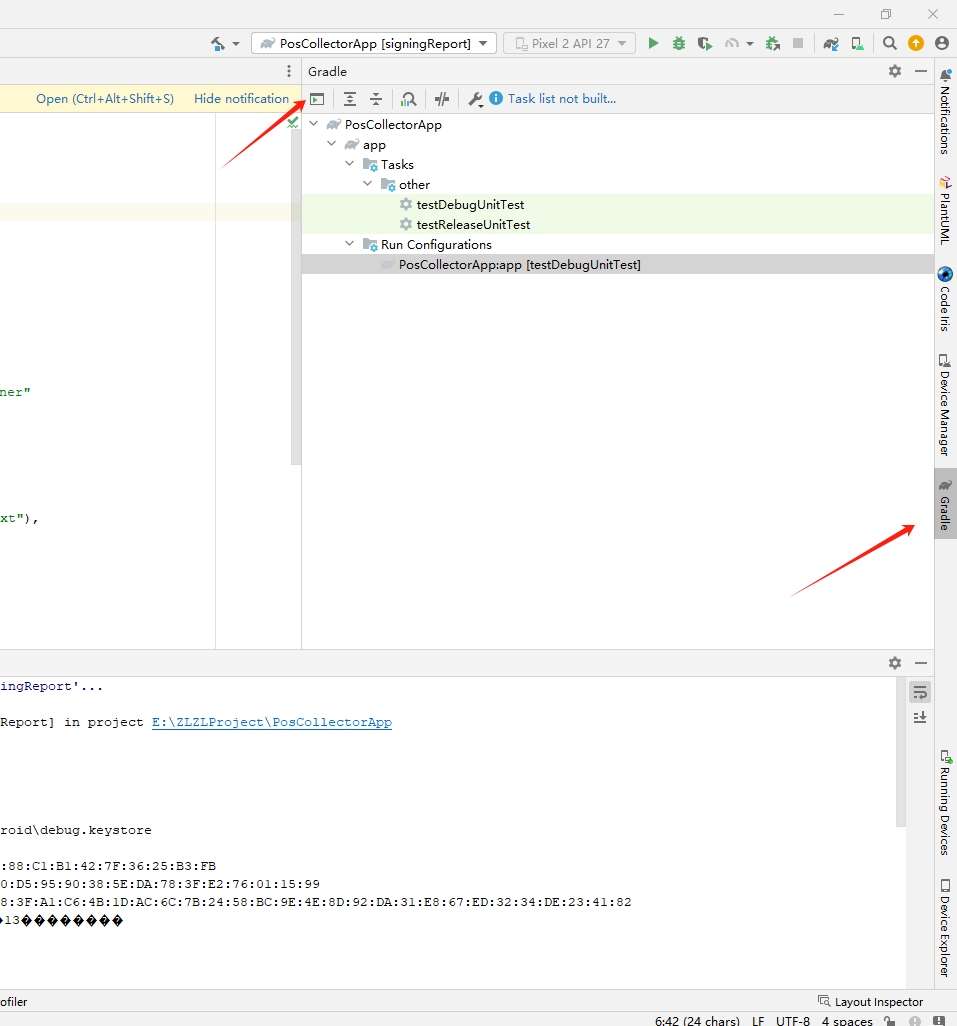
输出结果如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
Executing tasks: [signingReport] in project E:\ZLZLProject\PosCollectorApp > Task :app:signingReport Variant: debug Config: debug Store: E:\AndroidAVD\.android\debug.keystore Alias: AndroidDebugKey MD5: C2:AE:BC:4D:3B:2A:ED:88:C1:B1:42:7F:36:25:B3:FB SHA1: AA:F5:92:38:65:9F:B0:D5:95:90:38:5E:DA:78:3F:E2:76:01:15:99 SHA-256: FC:8E:3C:E0:80:78:3F:A1:C6:4B:1D:AC:6C:7B:24:58:BC:9E:4E:8D:92:DA:31:E8:67:ED:32:34:DE:23:41:82 Valid until: 2051��12��13�������� ---------- Variant: release Config: null Store: null Alias: null ---------- Variant: debugAndroidTest Config: debug Store: E:\AndroidAVD\.android\debug.keystore Alias: AndroidDebugKey MD5: C2:AE:BC:4D:3B:2A:ED:88:C1:B1:42:7F:36:25:B3:FB SHA1: AA:F5:92:38:65:9F:B0:D5:95:90:38:5E:DA:78:3F:E2:76:01:15:99 SHA-256: FC:8E:3C:E0:80:78:3F:A1:C6:4B:1D:AC:6C:7B:24:58:BC:9E:4E:8D:92:DA:31:E8:67:ED:32:34:DE:23:41:82 Valid until: 2051��12��13�������� ---------- BUILD SUCCESSFUL in 795ms 1 actionable task: 1 executed Build Analyzer results available 14:36:24: Execution finished 'signingReport'. |